So we are in the process of rewriting everything toward SimGrid 4.0. The main goal is to gain in clarity and maintainability, so that others can come and contribute to this tool. Thus the switch to C++. Thus the switch to the standard library.
Another big move is the reification and unification of the process synchronization activities. As explained in my HDR, SimGrid sees communication very similarly to a mutex or a semaphore: an actor can get blocked onto a communication or an execution just like it can block waiting on a mutex. This strong idea simplifies a lot of things in the implementation, since a long time.
But until now, the concepts were similar between comms, execs and mutexes, but both the APIs and the implementations were rather different. Things are greatly improving in S4U. From the user POV, and the methods provided by activities are now much more consistent, with init(), start(), and wait() provided for every activity. async() is just like init()+start() and a method is provided to do the combo init()+start()+wait(). The name of that method depends on the activity: Mailbox::put() is Mailbox::put_init()+start()+wait(), etc.
This post aims at describing what we would like to have at the end. Some parts are already implemented, others will follow. Some parts of the described design will probably change as we find the defects while implementing it.
Disclamers! this post is probably very difficult to read if you don't have a good understanding of what SimGrid is intended for. Also, this is rather long, so relax and sit down before you dive into the mud that currently fills my head. Feedbacks welcome. Also, the ideas presented in this post are not all mine. SimGrid is a joint effort of many people, sorry for not citing everybody here but the text is already too long and hard to read.
The Activity Automaton
Each activity entails have one such automaton, regardless of whether it's a communication, an execution or any other activity.
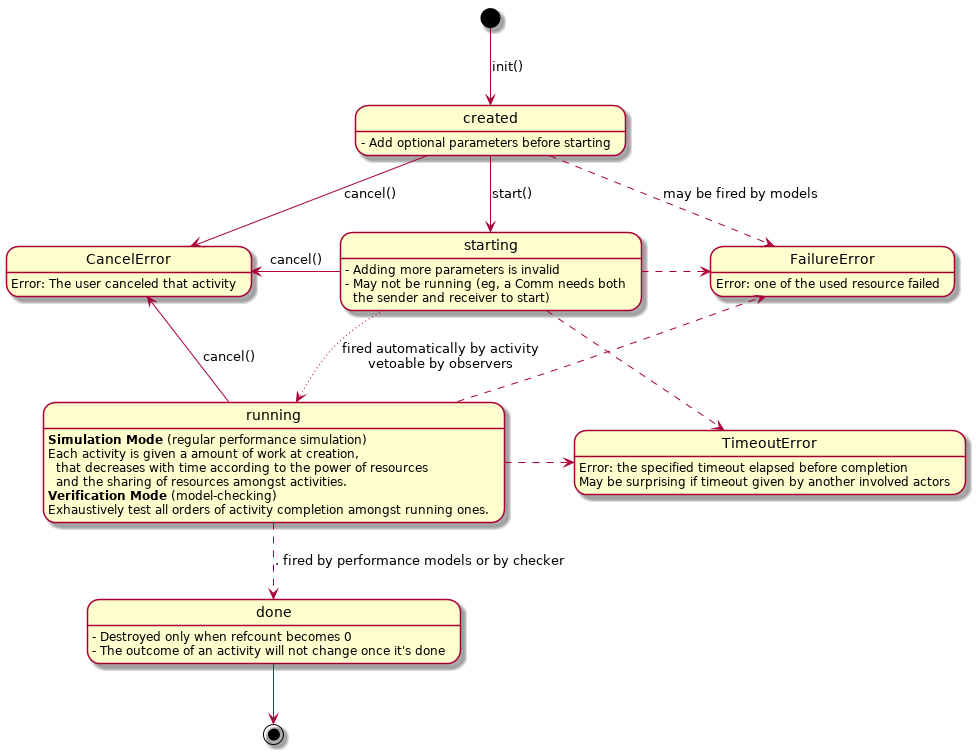
You see that the transitions may be fired by the actors directly (eg by calling activity.start()). The dashed transition are fired by the models, according to the platform. For example, when an host fails in the platform, all activities using that host are marked as failed and the actors waiting on that activity will get a proper exception.
The dotted transition will be fired automatically by the activity once the actor called start(). But the semantic of an activity may forbid to fire this transition right away. For example, communications cannot actually start until both the sender and the receiver call start(). Also, this transition can be vetoed by specific observers, in charge of checking additional, application-specific things. For example in the new SimDAG, this will be used to enforce that an activity cannot start before all its dependencies are done.
Co-Activities are the new ptasks
Parallel tasks were introduced back in the age to abstract away a parallel kernel. In some sense, a ptask is a big blurb that consumes both computation and communication resource. It's an interesting idea (heavily used by SimDAG users), but for some reasons it forces to use another approach to the resource sharing. Usually, we express the problem to solve as a linear MaxMin system (for which we implemented a very efficient solver), but since Apples don't mix well with Oranges, MaxMin does any sense if you mix flops and bytes. The bottleneck sharing that we use instead is kinda working in practice, but it does not allow us to express cross-traffic and slow-start effects: this seems to be simply impossible from a theoretical point of view.
So, at some point, we will generalize the concept of ptask into CoActivities. In addition to mixing CPU and network (for parallel kernels), you will be able to mix network and disk (migrating VMs or streaming data, hu?) or CPU and disk (out-of-core computations, maybe?), or anything else. But as in the existing code, you will have to choose between these abstract blurbs and the fine modeling of slow-start and cross-traffic effects. Sounds like a fair deal, right?
This fits nicely into the Activity Automaton diagram: computing when a started activity is done is a bit harder from the models point of view, but that's the same conceptual story.
Implemented classes
From the implementation point of view, the following classes are already in place but the code is still very messy. Large areas are still written in the procedural style. But anyway, here is what we will have:
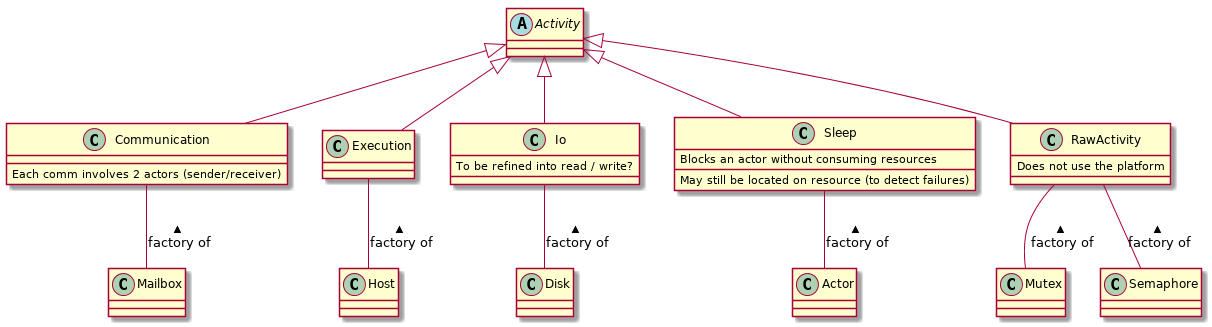
Note that activities cannot be created directly, but only through factories. This is because we use the pimpl pattern to hide the implementation of every s4u classes (and enforce the isolation of actors through simcalls, see below). In addition, instead of having the s4u interface and its implementation cross-referencing each others, the interface is actually a field of its implementation. That implementation point may change at some point because it complicates things sometimes -- will see.
The IO and Disk-born activities are currently under rewrite (by Fred), so I think that this will also evolve at some point. We may decide to make the Io class abstract, and derive Read and Write activities. We will do so on need, not before.
The RawActivities come from mutexes and semaphores. Currently, the Mutex object does most of the work that should be done by the activity. It's more efficient since there is so little to do for these activities that we don't really need to create an activity, but it's not fitting our Big Plan so I think we'll change it.
Speaking of which. We lost a lot of performance during the switch. I know. But the goal was to get a code that is nicer to work with, even if it degrades the perf by up to 25% compared to the old, brutal and pure C design. The refcounting added in 3.16 had a bad impact (over 10%), so I guess that we should use more of std::move to avoid changing the refcount. But our current control flow in these functions is not std::move()-friendly, as we often have 2 copies of the object existing for a few lines of code. Untangling this promises to be a lot of fun, that I reserve for later.
Another big performance sink is that we malloc a new activity each time we need one. We used to have mallocators to pool the resources instead. Restoring this in the right C++ way is very feasible, but not right now.
The actor point of view
Activities have a central role to understand how actors interact, that we will explore now. In SimGrid, each actor has its own execution context, and the maestro is an extra execution context in charge of scheduling the actors. This allows the users to write their application to simulate in a way that is very close to real applications. Each actor can be seen as a sort of thread or process, with a stack and local variables. Under the hood, the control flow switches as follows between execution contexts:
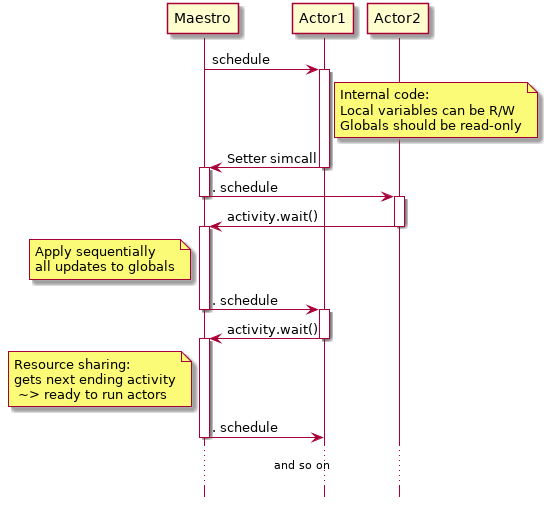
From the conceptual point of view, each actor run in a perfectly isolated environment. It can freely read the state of its environment, but each time it try to modify the environment controlled by SimGrid, the actor gets descheduled (maestro gets the control back). After the execution of all actors that were ready to run, any queued updates to the globals are executed in a sequential and predictable order. This is mandatory to run all actors in parallel on the host machine. But this may not be sufficient. Since there is no system-level isolation, you should also properly synchronize the access to the global variables shared between your actors, if you have any. That is why parallel execution is not activated by default, even if we consider this feature as stable (if you don't use SMPI nor Java).
If you don't plan to use parallel simulation, this paranoid isolation of the processes can be a bit annoying because it's hard to predict which SimGrid function may deschedule your actors. If you have any idea of how to do improve this, please speak up! And no, listing the interrupting calls will probably not be sufficient: such lists are near to impossible to keep up to date, and we may oversee calls ourselves too. We'd need some sort of support from the compiler.
This whole discussion connects back to the purpose of this post because the previously described process repeats until all actors are blocked on an activity, wait()ing for its completion. Once this is the case, maestro must advance the simulated time up to the point where one of the activity ends, so that it unblocks some actors, that will be scheduled.
In the SimGrid insider parlance, what's depicted above is a Scheduling Round, composed of 2 sub-scheduling-rounds. This gives the following pseudo-code for the main loop of SimGrid:
Initialize all the things While there is some actors to run: # The body of that loop is a Scheduling Round | While some actors can run without advancing the clock: # this is a subscheduling round | | For each such actor, schedule it and wait until it blocks again | | Serve all actor requests that we can serve without advancing the clock | Decide which blocking activity should be unblocked: | | In simulation, share the resources, and compute the earliest ending activity with this | | In verification, the checker algorithm will pick one visible activity to explore. If some actors are still blocked, since there is no pending or potential action, that's a deadlock. Report it. Otherwise, report the successful termination of the simulation.
SimGrid as an Operating System
Switching between the execution contexts is clearly in the critical path of any SimGrid simulation. We have several implementations of the execution contexts, that we call context factories. One is using system threads, be they pthreads or windows threads. But threads are bloated with features we don't need, so this implementation is more robust and much slower. Other context factories are are using old standards (System V uncontexts) or third party libraries (boost). The Java bindings use a specific factory that registers system threads into the JVM as it should. Our fastest factory is directly implemented in assembly, and does the absolute minimum that we need. It naturally yields the best performance, and it's rather portable too. It will be automatically picked if you have a x86 or a amd64 processor. Windows is an exception since our code is broken on that OS (Windows portability is a whole story by itself), but it work for Linux, Mac, FreeBSD and NetBSD.
Regardless of the context factory, the interaction between the maestro and the actors is very similar to what happens in an operating system. After all, the syscall mechanism is meant to isolate the actors from each other and to mediate their interaction with their environment. Exactly what we need here in SimGrid. Simply, we don't call it syscalls, but simcalls.
When an actor want to request something from the maestro, it writes the request type and parameters in a specific area of its private memory, and then return the control (context switches) to the maestro. The latter queues the actor that just returned control into the list of actors to run during the next sub-scheduling round, and proceed to the next actor of the current round. Once the round is over, the maestro iterates over all actors again, serve the requests that are not blocking, and creates or update the Activities on which actors are blocked. The will get unblocked when the simulation models decide that the activity is done.
The Model-Checker point of view
Surprisingly, the whole design that we built up for the performance of parallel simulation make it possible to turn SimGrid into a specific tool for the formal verification of distributed programs and algorithms. This is particularly interesting since many middle-sized MPI codes run without modification on top of SimGrid, and thus within the Checker.
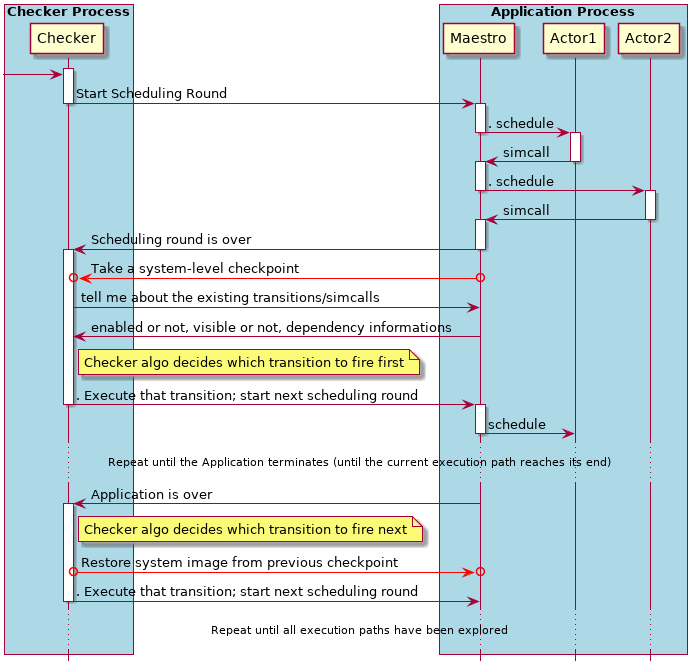
To make this happen, we replaced the part of SimGrid that computes the next occurring event according to the platform sharing and everything, with an exhaustive exploration mechanism. At the end of your scheduling round, if you have 3 activities t1, t2 and t3 that are running (in the formal parlance you say that these transitions are enabled), first explore the scenario where t1 is fired first (where the corresponding activity finishes first). Then rollback your application to the point right before you fire t1, and explore the scenario where t2 is fired first. Then rollback again and try firing t3. In some sense, our formal verification comes down to testing a given application with a given set of input parameters on all possible platforms at once.
One building block is the ability to checkpoint and restore the verified application. We do so at system level, by reading all OS pages of the currently running application, store them somewhere so that we can restore the system image of the application on will. You don't want to restore the Checker data but only the application, so the Checker and the Application live in separate OS processes (what we call Application here is very similar to a simulation, amputated of all models).
Once your model-checker actually works, you discover that verifying any stupidly simple property and application exhaust the biggest machines that you can access. Naive verification requires an exponential amount of time and of memory.
Concerning the memory, taking one full snapshot of your application after each scheduling round is appealing but not doable. You could take only one snapshot at the beginning of the application, and replay the beginning of the execution path up to the point where you want to fire another transition. But then, this makes the process even longer. Instead, our solution is to take and restore snapshots at the OS page level. For each page of the Application that we need to save, we determine whether or not it was previously saved (using a simple hash function + a byte per byte comparison if the hash matches). Similar pages will only be stored once across snapshots, dramatically reducing the necessary memory. The price to pay is the relative complexity of the book keeping to later restore all pages pertaining to the snapshot that you consider. I'm happy that this code is written and relatively well tested because it's not the most pleasant part of SimGrid to work with. Applause Gabriel Corona for that code, not much people could have done that.
Concerning the time, the amount of possible event interleavings (the amount of execution paths to explore) grows exponentially with the amount of events. The good thing is that you can easily build equivalence classes between these execution paths (such as Mazurkiewicz traces or others), so you want to implement a nice state-space reduction algorithm to exponentially reduce the amount of paths to explore.
DPOR is one such classical algorithm, exploiting the idea that some events have no mutual impact, such as local events to differing hosts (such events are said to be independent). If you know that events t1 and t2 are independent, and if you already explored the trace with t1,t2 then you don't need to explore the trace with t2,t1 because that would lead to the exact same result. We implemented DPOR in SimGrid around 2010, and it works fine. As a side note, we simplified the algorithms found in the literature because our actors can only have transition enabled at a given time (they return only one simcall at a time), but this was an error. In MPI, you have this call WaitAny, that blocks onto a vector of communications and unblocks as soon as one of these comm terminates. The right way to represent that to the Checker is to say that the corresponding actor has vector of enabled transitions, but we did not do it this way. Instead, we rewrite the WaitAny simcalls into atomic Wait simcalls, but that's messy. I hope to simplify this away before SimGrid 4.0. The checkers algorithms should be improved for that.
Another messy spot that should be sorted out is the part where the checker algorithm gets information about the existing transitions and their status. It is currently implemented by remotely reading the memory of the Application from the Checker. Yep, we open the /dev/$pid/mem of the Application, and directly interpret what we read from the Checker. Even if it reuses the low-level mechanism of the snapshoting thing, it makes the code cluttered and forbids to use advanced STL structures in SimGrid part of the Application: their implementation is compiler dependent, and the Checker would be able to interpret the memory layout. Instead, we should do cleaner RPC calls as depicted in the above diagram. That's ongoing.
As implied earlier, SimGrid implements several Checker algorithms. The Safety Checker exhaustively search for a state where one of the assertion provided in the source code fails. So the properties are simple propositional assertions. In practice, that's a boolean function evaluated in the application. Searched counter examples are states in which these functions return false.
The Liveness Checker algorithm enforce much more complicated properties, expressed in Linear Time Logic. That's just as propositional logic but you get some quantifiers about the time too. You can say "property P always become true at some point of the execution path" or "on every execution path, property P become true after a while, and remain so until the end of the path" or "If P ever becomes true, then Q will become true in a finite amount of steps".
Verifying these is a bit more difficult because the counter example is not just one state, but an infinite path (eg. where P became true but Q never becomes true). For that, we encode the opposite of the desired property into a Bucchi automaton (a classical representation of infinite paths), and the verification process actively searches for an execution path that is accepted by this automaton. If we find one, we have a counter-example to the property. If we cannot find any, then the property holds on the Application. Also, Bucchi exploration requires to detect exploration loops: when the Application reaches the exact same state as previously. Solving this challenge at the OS level was the main contribution of Marion Guthmuller's PhD thesis, a few years ago. We manage to interpret the application memory just like debuggers such as gdb do, and we manage to detect state equality without any hint from the user in most cases. This part is really tricky, believe me.
The Determinism Checker is a third algorithm, that can determine whether the Application is send-deterministic, ie whether it always send its outgoing message in the exact same order (locally to each actor). This is important to the HPC community because you can leverage distributed checkpointing algorithms that are much more efficient if you know for sure that the application is send-deterministic. The difficulty is that you cannot express this property in LTL because you need to speak not only of the past and future of the current execution path, but also of all possible future execution paths. You need a time logic that is not linear, but branching. You get something as "There exist a order of outgoing messages that is verified for every possible execution path". Our trick is run a random exploration, and learn the message order on that branch. Once we know that, the property can be reformulated as "The current execution path respects the provided message order", which is actually a LTL property and can be verified as earlier.
SimGrid also implements several state-space reduction schema. DPOR was described earlier: it will not explore a new trace if it only differs from a previously explored trace by the exchange of two independent events. Our implementation is only applicable to safety properties, as it tend to cut the cycles that the Liveness checker searches.
The state equality reduction cuts the current execution path if it reaches a state that was already explored earlier. It's usable with all our Checker algorithm, but cannot be used in conjunction with our of DPOR, because DPOR needs to reach a final state to determine the transition to consider next at branching point of the exploration.
As part of his PhD, The Anh is currently exploring how to use event folding structures to reduce the state space, in a way that would be compatible with all our Checker algorithms (hopefully). It should be more efficient than what you could possibly gain from using DPOR and state equality jointly if it were technically possible.
My long term goal is to make it possible for others to implement another checker or reduction algorithms in SimGrid, even if they are more fan of theoretical formal verification than of the required OS plumbering. We are still far from it, but that's my goal. But the good thing is that I am rather convinced that the Activity concept discussed in this post should be really helpful for that.
Conclusion
Conceptually, things begin to settle down on our path toward SimGrid 4.0. The activities will help unifying and simplifying a lot of stuff in our code base, while giving more power to our advanced users. That's highly motivating. Writing this post helped me sorting my ideas; we can proceed with the implementation now.
I should also write such blog post about the other points that I see as driving ideas for the design of SimGrid 4.0, such as how the observer pattern will help us writing modular code and plugins extending the behavior of SimGrid in a very specific way.
Another design challenge is on the creation of composable and extensible platform models. SimGrid 4.0 will allow to have more than one performance model within the same platform, thanks to our notion of hierarchical Routing Zone.
Sorry for this long post, I needed to sort my ideas...