Predicting saliency using two contextual priors: the dominant depth and the horizon line
O. Le Meur
ICME 2011
Main Idea
A computational model of visual attention using visual inferences is proposed. The dominant depth and the horizon line position are inferred from low-level visual features. This prior knowledge helps to find salient areas on still color pictures. Regarding the dominant depth, the idea is to favor the lowest spatial frequencies on close-up scenes whereas the highest spatial frequencies are used to predict salient areas on panoramic view. Some studies showed that the horizon line is a natural attractor of our gaze. Horizon detection is then used to improve the saliency prediction. Results show that the proposed model outperforms existing approaches. However, the dominant depth does not bring any gain in the saliency prediction.Original figure of the paper
Click on the pictures to look at the original picture.- Figure 1:
- Figure 2:
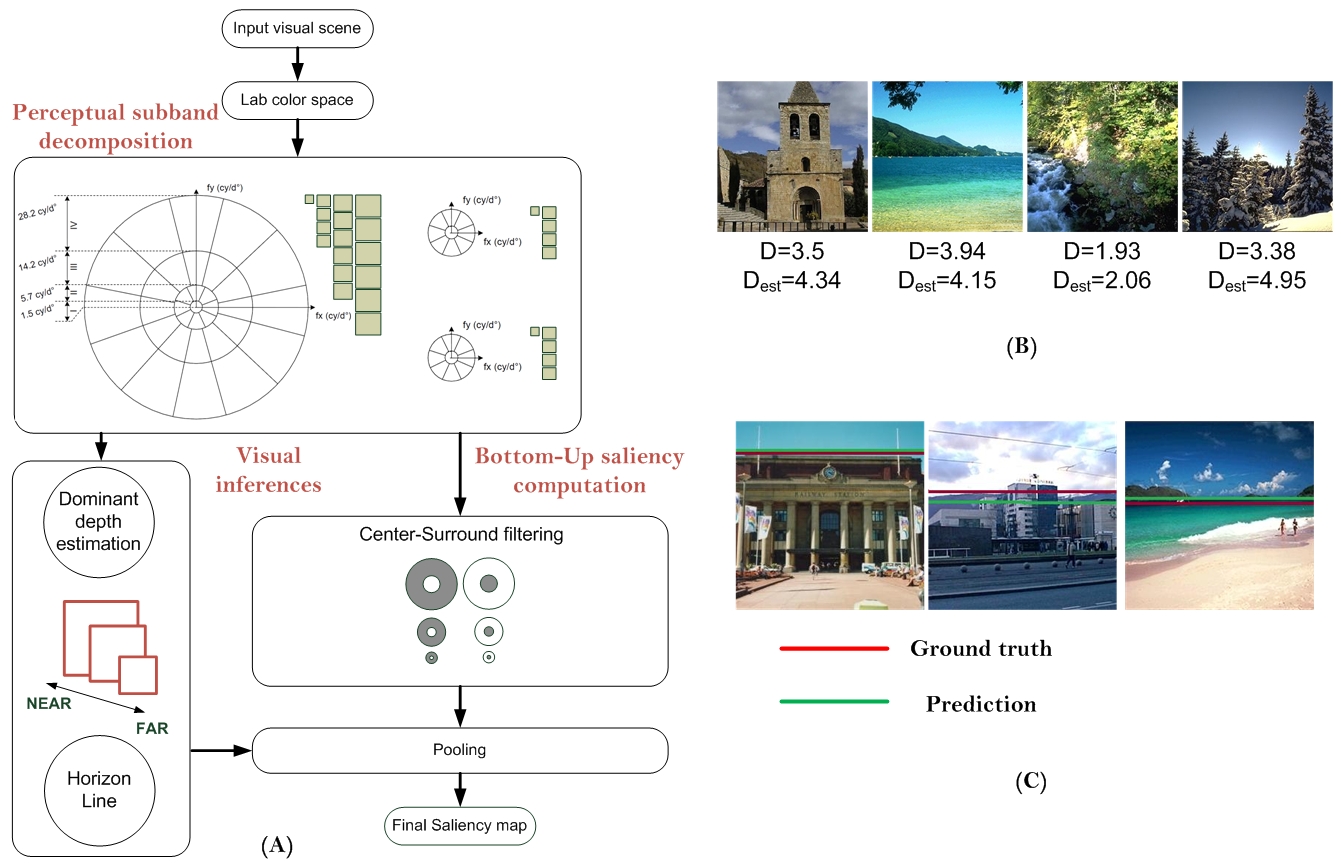
(A) Synoptic of the proposed approach. The input visual scene is projected into the Lab color space. A hierarchical decomposition is performed in the Fourier domain. Depth and the position of the horizon line (if any) are used to adapt the saliency computation. (B) Inference of the dominant depth based on a machine learning (D and Dest represent the ground truth and the prediction of the dominant depth, respectively). (C) Inference of the position of the horizon line.
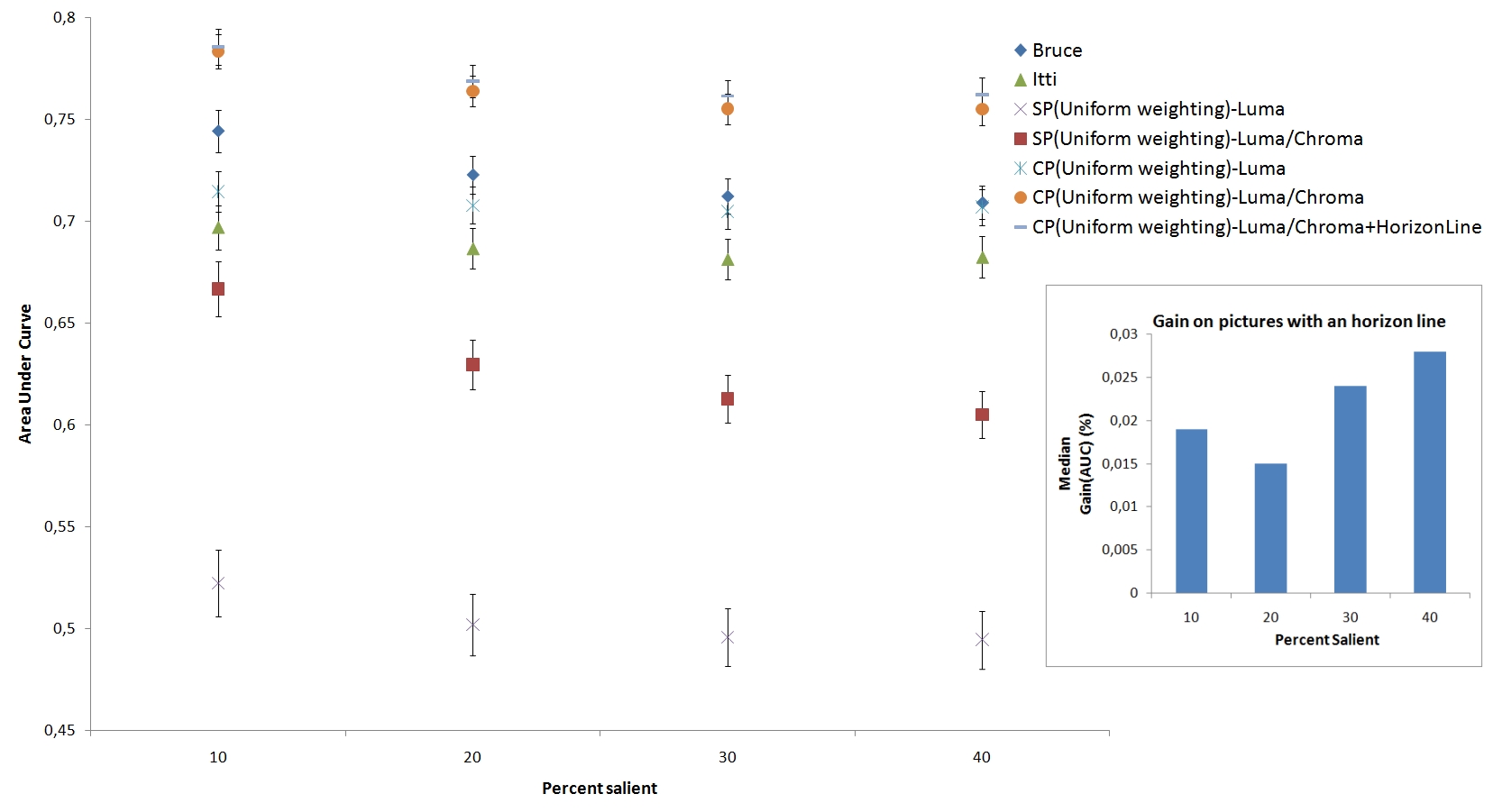
AUC value for the different versions of the proposed model. The performance of Itti's and Bruce's model is also given. On the bottom-up right, the median gain brings by the use of the horizon line is shown. For pictures having an horizon line, the gain is about 2 percents.
Supplementary materials
Horizon line inference: the green line is the estimated position of the horizon line.






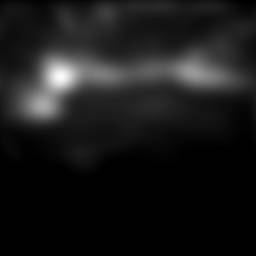
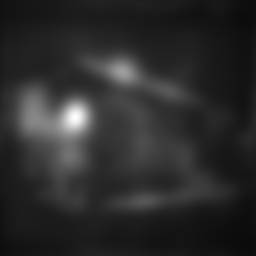
Qualitative comparison: from left to right: original picture, saliency map without contextual influence, saliency map with contextual influence.














































Software
Not yet available.BibTex
@InProceedings{LeMeur_2011,
author = {O. {Le Meur}},
title = {Predicting saliency using two contextual priors: the dominant depth and the horizon line},
booktitle = {ICME},
year = {2011}
}