It has been a while that I didn't report any progress on JLM, but I'm still full of ideas about it. I'm still sure that it's one of the best proposal out there to help people learn programming, and I have about 12 ideas of improvement per hour. I'll try to present some of them here, to organize my head a bit on this section. The Java Learning Machine (JLM) is one of my favorite pet projects. It's an integrated environment to learn programming through graphical exercisers based on several graphical micro-worlds, adapted to the learned notions. Well, I admit I cannot find any useful definition for this tool, you'd better check it out.
Backtracking lesson
I have an experimental lesson aiming at teaching students about backtracking. It is not ready for consumption yet, not even the first exercises. It will feature several exercises on the topic allowing to progressively build the relevant notions and mental representation in the students mind.
For now, it contains a Backtracking exercise which lacks a graphical representation to be usable (see below). That's too bad because that's this graphical interface which is useful. The following textual representation is very great to actually understand what's going on, but I'd like to go one step further and actually build the call tree automatically.
| What I have right now | What I'd like to have |
Compute answer for world knapsack(max:10; 2, 2, 4, 4) solve(0,[--, --, --, --]); bestSolution so far:null solve(1,[2, --, --, --]); bestSolution so far:null XXXX New best solution: [2, --, --, --] solve(2,[2, 2, --, --]); bestSolution so far:[2, --, --, --] XXXX New best solution: [2, 2, --, --] solve(3,[2, 2, 4, --]); bestSolution so far:[2, 2, --, --] XXXX New best solution: [2, 2, 4, --] solve(4,[2, 2, 4, 4]); bestSolution so far:[2, 2, 4, --] solution invalid, backtrack solve(4,[2, 2, 4, --]); bestSolution so far:[2, 2, 4, --] depth too large: 4 solve(3,[2, 2, --, --]); bestSolution so far:[2, 2, 4, --] solve(4,[2, 2, --, 4]); bestSolution so far:[2, 2, 4, --] depth too large: 4 solve(4,[2, 2, --, --]); bestSolution so far:[2, 2, 4, --] depth too large: 4 solve(2,[2, --, --, --]); bestSolution so far:[2, 2, 4, --] solve(3,[2, --, 4, --]); bestSolution so far:[2, 2, 4, --] solve(4,[2, --, 4, 4]); bestSolution so far:[2, 2, 4, --] XXXX New best solution: [2, --, 4, 4] depth too large: 4 solve(4,[2, --, 4, --]); bestSolution so far:[2, --, 4, 4] depth too large: 4 solve(3,[2, --, --, --]); bestSolution so far:[2, --, 4, 4] solve(4,[2, --, --, 4]); bestSolution so far:[2, --, 4, 4] depth too large: 4 solve(4,[2, --, --, --]); bestSolution so far:[2, --, 4, 4] depth too large: 4 solve(1,[--, --, --, --]); bestSolution so far:[2, --, 4, 4] solve(2,[--, 2, --, --]); bestSolution so far:[2, --, 4, 4] solve(3,[--, 2, 4, --]); bestSolution so far:[2, --, 4, 4] solve(4,[--, 2, 4, 4]); bestSolution so far:[2, --, 4, 4] depth too large: 4 solve(4,[--, 2, 4, --]); bestSolution so far:[2, --, 4, 4] depth too large: 4 solve(3,[--, 2, --, --]); bestSolution so far:[2, --, 4, 4] solve(4,[--, 2, --, 4]); bestSolution so far:[2, --, 4, 4] depth too large: 4 solve(4,[--, 2, --, --]); bestSolution so far:[2, --, 4, 4] depth too large: 4 solve(2,[--, --, --, --]); bestSolution so far:[2, --, 4, 4] solve(3,[--, --, 4, --]); bestSolution so far:[2, --, 4, 4] solve(4,[--, --, 4, 4]); bestSolution so far:[2, --, 4, 4] depth too large: 4 solve(4,[--, --, 4, --]); bestSolution so far:[2, --, 4, 4] depth too large: 4 solve(3,[--, --, --, --]); bestSolution so far:[2, --, 4, 4] solve(4,[--, --, --, 4]); bestSolution so far:[2, --, 4, 4] depth too large: 4 solve(4,[--, --, --, --]); bestSolution so far:[2, --, 4, 4] depth too large: 4 Solution:[2, --, 4, 4] Load lesson lessons.meta Add Create world exo Add Create entity exo Compute answers 3 Solve(0,1) Solve(1,2) Solve(2,0) |
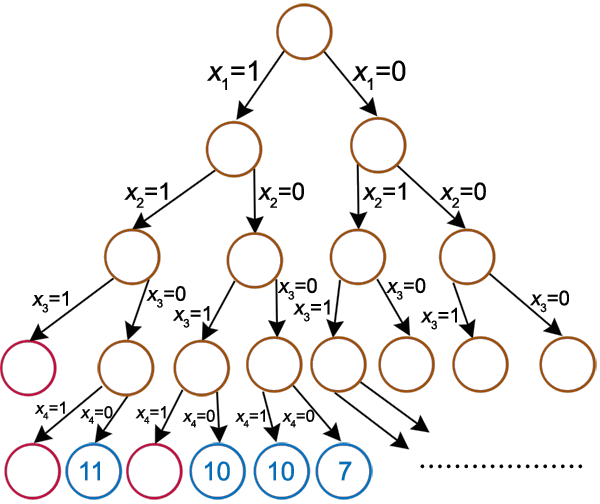
(sample picture from interstices, almost representative of what I really have in mind. I'd like to have better representations of each nodes. This is for example important for the N-queens problem) |
Technically, it is based on an entity KnapsackSolver which works on a KnapsackPartialSolution. This latter is not a World nor an Entity, but a passive world component. It is used by the solver to store the currently best solution and the working solution. This design should be rather generic and other backtracking problems, such as the ones used in my TOP teaching (pyramid or recipients) should be implementable following this design. That is why Backtracking classes derive from generic ones: BacktrackingEntity and BacktrackingPartialSolution. There is also a BacktrackingWorld, that specific universes should need to not override, and BacktrackingExercise, dealing with this specificity where the world does not only contain solving entities, but also two partial solutions (best know and current).
This exercise should be introduced by an interactive discovery activity such as the one used on interstices, but that's not my top priority right now: no need to introduce something that's not working.
Although this exercise seems almost usable, there is a fundamental difficulty to solve in the visualization. It is envisioned that the call graph is used here, to help the students building their mental representation of recursion. The actual representation of the graph should be quite easy, thanks to the jung library (see this example). But I fail to see how to get the needed info so far. Adding sensors to the stepUI() method is probably the best way to go, but I would need to inspect the complete call stack where Thread.currentThread().getStack() only give the static stack (method called, file location, etc). I think I need to inspect the parameters passed to each method call to rebuild the proper call tree.
The first thing that I tried to use was dtrace, but it seems non-portable and somehow linked to Solaris so I didn't dig any further.
Then, I tried to use the debugging infrastructure (JPDA), but never managed to get it working. It seems to me that the original com.sun.jdi package is somehow deprecated since com.sun.jdi.BootStrap.virtualMachineManager() returns null while org.eclipse.jdi.Bootstrap.virtualMachineManager() does not. But when I'm using the eclipse version, it seem to take an endless amount of dependencies, which I'm not inclined to do. The root of my problem may be that I was using a jdi.jar coming from eclipse, but I didn't find any other. I just realized that the com.sun.jdi package is also implemented in /usr/lib/jvm/java-6-sun-1.6.0.26/lib/tools.jar on my disk. It seem to be functional, I should give it another spin.
Afterward, I tried to reuse the debugging infrastructure of DrJava. It looks like a good idea because they have several helper interfaces for debugging and compiling. Also, they have a good editor that we could reuse. Finally, they have a strong testing infrastructure with junit ensuring that their tool still work after modifications (that's something we are seriously missing in JLM). I'm really thinking that the two tools should converge to something stronger. The only argument for not doing so (beside the amount of work it'll take) is that each of us get the credit for each tool where things would be more fuzzy on a mixed tool. But I don't care, the mixed tool would be so much cooler that I'd like to find the time to ensure this convergence. Speaking of tool convergence, I also think that CodingBat presents some really interesting features. The ones I'd like to integrate into JLM are the editorial work on the lessons, the encyclopedia which can act as a reference manual about Java programming and the fact that teachers can very easily build a lesson for their students by picking exercises from the list, and then follow the progress of the students using the tool. The teacher interface is definitely a point on which JLM is seriously lacking proper support.
To come back on my backtracking lesson, the sad news is that the debugging feature of DrJava seems to suffer from an issue: http://sourceforge.net/tracker/index.php?func=detail&aid=3004294&group_id=44253&atid=438935 I was suspecting a permission error (something related to com.sun.jdi.JDIPermission), but even with a java.security.AllPermission as permission file, I still have the issue.
Another lead to get it working it to use lib ASM to modify the student code so that their recursive method gets traced. With the static backtrace and the tracing information, I guess I could rebuild the actual call tree. According to what I see after 2 sec of googling, that seem to be possible.
So, here I am. The lesson would be very interesting to students, and quite easy to finish once I manage to get the information I need, but I didn't manage to do so so far, despite my efforts. If you have any hint (or patch!), please email martin.quinson#loria.fr.
Spreading the good news
I'm also working on ensuring that potential users know JLM. The thing is that I'm ok with developing it further, that's fun and I think that it's a great too. But I need more users to feel that this work is really useful to something. That is why we submitted an article to SIGCSE'11: in the hope that the teachers that read these proceedings will learn about our tool and maybe bootstrap a community of users. But the article was unfortunately rejected, but the reviews are quite informative, and I'm in the process of improving the paper. The next opportunity to increase the tool community through a paper is SIGCSE'12, but the deadline is on September 2., I'm not quite sure that I'll manage to be ready by the end of the summer unfortunately.
Another way to increase the tool visibility is its ongoing integration within Debian. I am officially working on it, and the main blocking point is the fact that we use twitter to post the progress of the students, and the library we are using for that is not packaged into Debian yet. Even worst, it cannot be packaged as is because of licensing issues. So, I should remove the twitter support, but I need to fix the lesson text accordingly and that's a stupid and neat feature. Another solution would be to switch to identi.ca, which is even more cool since it's open, and with which I shouldn't face any licensing issue. But so far, I didn't find the time to investigate it any further.
I should also find opportunities to spread my tool through the new computer science option that will soon be created at lycée, our K-19 classes. That's one of the multiple point where I feel invested. I'll say more about it when I'll have any concrete elements to report on.
Improving the modularity and breaking the linearity
When I look at CodingBat, I feel that we missed something when designing JLM. We identified 2 groups of users: the students that take the exercises, and the teachers that write these exercises. But the reality is that there is 3 populations around such a tool: the students, the authors that write universes (as we call micro-worlds dedicated to a learning situation) and exercises (specific learning situations) from scratch, and the teachers that reuse existing exercises and adapt them to fit their needs and visions.
In CodingBat, teachers can pick the exercises they want to present to their students from the list, and mask the others. In JLM, the lesson we use in ESIAL is hardcoded and you have to recompile the application if you want to adapt the text. That's definitively something I want to improve. For that, I need the exercises to be more self-contained where the text of one exercise sometimes compliments about the previous one. Other exercises contain basic explanations about the studied notion (such as for loop or variable), making it impossible to mask this very exercise, and difficult to move in the sequence.
Going further on this lead, we could have the sequencing of exercises not hardcoded by the lesson, but given by dependency rules. It could either be a system similar to the linux packages (you need to solve this and that exercise before tackling the current one), but it could also be more game-oriented. We could take a list of competencies and say that students cannot try a given exercise until they have the required amount of points in certain competencies. Then, once they are passed successfully, they grant points in [other] competencies. For the competency list, we could use the one presented in the lesson documentation of the first lesson (depicted below), or a better one: I designed this one in a real hurry.
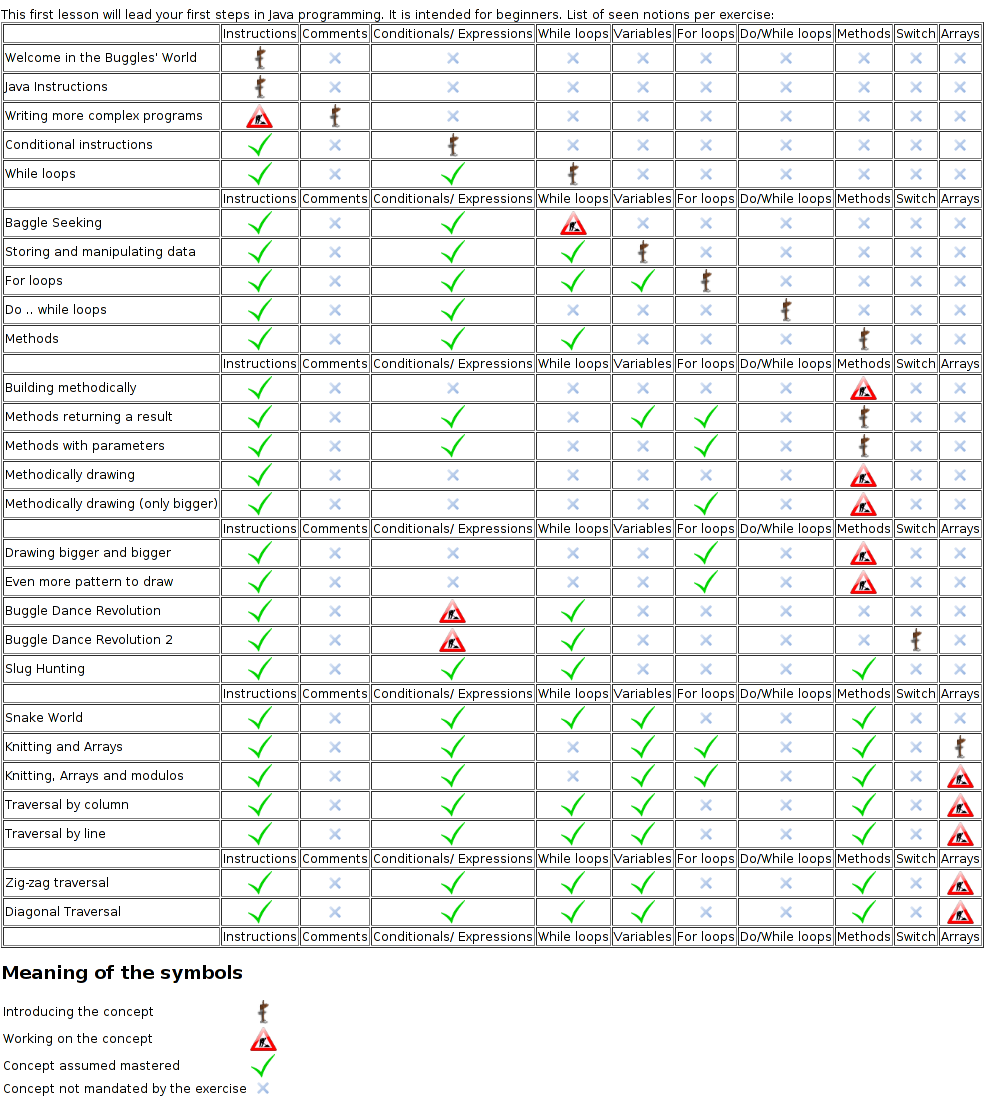
This would mean for example that to take the Baggle seaking, you'd need at least 3 points in instructions and conditionals, and that it would grant you 1 point in while loops. This would be interesting in the sense that JLM would be more of a game, and exercises would be more independent of each others. Teachers would be free to modulate their lessons by picking some of the existing exercises to get their students through the wanted path, or write their own exercises if they want.
Once again, that's a neat idea that would really improve JLM and only need a week or two to get drafted, but I need to do it...
TODOs
All this gives me the following todo actions:
Check whether tools.jar gives a working com.sun.jdi package
Find the DrJava bug around debugging to help them, and so that I can steal parts of their code about it for JLM (it's BSD'ed while JLM is mainly GPL'ed for now -- I'll have to ask them for an exception). That would be better since their helper interface seem to be able to deal with several debuggers (eclipse, sun or openjdk). That's quite a large amount of work I'd like to avoid dupplicating.
Check whether I can get tracing info from ASM. It may be more robust to JVM variants than the debugging approach. On the other hand, debugging is a neat feature for JLM as is.
Work on the convergence of JLM and DrJava. Beside of the licensing issue, it will also complicate the ongoing integration of JLM within Debian, since DrJava is composed of 5 separated modules that can only be integrated as separated source packages. As every java package, no source archive is distributed, and they must be retrieved directly from the svn. Finally, they are quite huge, with sloccount reporting 92k sloc on DrJava, 12k on DynamicJava, 24k on JavaLangLevels and 23k on the plt helper library...
Check whether I can use identi.ca from java as easily as twitter to unblock the Debian packaging effort.
Reduce dependencies between exercises: Make sure that exercises can have a concluding text that get displayed after the exercise is solved. Make sure that any concluding text placed in the exercise following in the sequence is moved to the right place. Make sure that the lesson are placed into a sort of encyclopedia.
Implement an explicit, non-linear dependency mechanism between exercises. A proper list of competencies may be useful for that.
[This blog post have a follow up here: JLM getting live]